Simply stated, genetic programming (GP) is the process of "evolving" an algorithm to perform a particular task. GP is inspired by the notion of natural selection. It is similar to, but not quite the same as genetic algorithms (GA), in which the parameters of an algorithm are evolved in order to create a "fit" solution to given problem.
The applicability of GP for a particular domain depends on number of factors:
Note that in general, GP/GA will not yield the ideal solution to a problem, but often a "good" solution will suffice.
There are many on-line resources for information regarding GA/GP, use your favorite search engine to find them.
Gollem's genetic architecture extends traditional genetic programming in two primary ways.
For each of the above data-types, a large number of "manipulating functions" have been defined.
(Currently there are over 1,000 implemented functions and nearly 2,000 planned in total.)
Each function takes two collections of local data as an argument and each has access to the global
data as well. Some example functions include:
The b!Gollem genetic framework is based on a CPU model. Programs (individuals) take the
form of a sequence of atomic functions. These programs are
"run" on an engine that might be thought of as a CPU.
The CPU can be divided into two parts that loosely correspond to Read-Only Memory (ROM) and
Random Access Memory (RAM). We'll describe each portion in turn.
There are several "meta" functions within the function table that manipulate the registers,
copying or exchanging values and pushing/popping values from the stack.
The following list describes the genetic operators currently being used. The frequency of use
is determined by the breeding parameters dialog box described on
a previous page.
Global Data-Types
![]() Board
Board
![]() ChainMap
ChainMap
![]() Field
Field
![]() Log
Log
Local Data-Types
These data-types, together with the functions that manipulate them, form the foundation of Gollem's
built-in go knowledge.
![]() Bool
Bool
![]() Coor
Coor
![]() Color
Color
![]() Flavor
Flavor
![]() Float
Float
![]() Int
Int
![]() List
List
![]() Rect
Rect
Genetic Functions
Genetic Framework
The Central Processing Unit
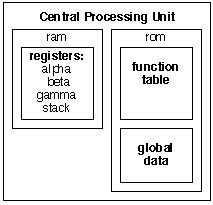
Read-Only Memory
The ROM portion of the CPU is composed of a function table, an array of
the atomic functions, and the global data types like the Board, et al.,
described above. The "read-only" description is somewhat inaccurate here, since the "internal
state" of global data types can be changed, but only indirectly. That is, the programs cannot
directly alter the global data types; they can only query them for information. The global data
types change, however, for each move made in the game.
Random Access Memory
The RAM portion of the CPU is entirely composed of local data types stored in registers.
Three registers, designated alpha, beta and gamma are individual
instances of the collection of local data types. A special stack register is an arbitarliy
large list of local data instances, stored in a standard "push-down" stack. Only the top-most
collection on the stack is available for reading or writing.
The Programs
An individual in the population is simply a sequence of integers that correspond to entries in the
function table. A program is run by calling each function in turn. In particular, each "atom" in a
program is composed of two parts. The first part specifies which registers are to be acted upon. For
instance, the same function can have dramatically different results when run upon registers alpha and
beta than it would when run with two "copies" of the gamma register. In this way each
entry in the function table corresponds to 16 different functions--one for each ordered pair of registers.
The remaining part of the atom specifies which entry in the function table to use.
The Genetic Operators
Breeding within the Gollem system is a fairly straight-forward implementation of GP. Since
the order of the functions within the table is arbitary, functions are bred as piece. The
"operator" (function) and "operand" (register) parts of each atom may be changed indepenedently.
A "chromosome" within the Gollem system is the sequence of atoms and it is these sequences that
are bred.
Parent: 1 2 3 4 5 6 7 8
The Child: 1 2 3 4 5 6 7 8
First Parent: 1 2 3 4 5 6 7 8
|
+---the point picked out
Second Parent: A B C D E F G H I J
|
+---the point picked out
The Child: 1 2 3 G H I J
First Parent: 1 2 3 4 5 6 7 8
| |
| +---second point
|
+---first point
Second Parent: A B C D E F G H I J
| |
| +---second point
|
+---first point
The Child: 1 2 3 E F G 7 8
First Parent: 1 2 3 4 5 6 7 8
Second Parent: A B C D E F G H I J
The Child: A 2 3 D 5 F G 8 J
Parent: 1 2 3 4 5 6 7 8
The Child: 7 4 1 6 5 8 2 3
Parent: 1 2 3 4 5 6 7 8
| |
| +---second point
|
+---first point
The Child: 1 2 5 6 4 3 7 8
Parent: 1 2 3 4 5 6 7 8
The Child: 1 2 A 4 5 B C 8
![]()
![]()
![]()